计算机组成原理
多线程
网络爬虫
postgresql
Pull APP
nginx
电气
随身wifi
新媒体运营
信息系统综合测试与管理
游戏程序
高校失物招领系统
hibernate
CalBioreagents
AQS
学生网页作业
Spark3.x
java面试
循环平稳检测
现代机器人学
word2vec
2024/4/11 18:26:57
【文本到上下文 #6】高级词嵌入:Word2Vec、GloVe 和 FastText
一、说明 欢迎来到“完整的 NLP 指南。到目前为止,我们已经探索了自然语言处理的基础知识、应用程序和挑战。我们深入研究了标记化、文本清理、停用词、词干提取、词形还原、词性标记和命名实体识别。我们的探索包括文本表示技术,如词袋、TF-IDF 以及词嵌…
Word2Vec进阶 - ELMO
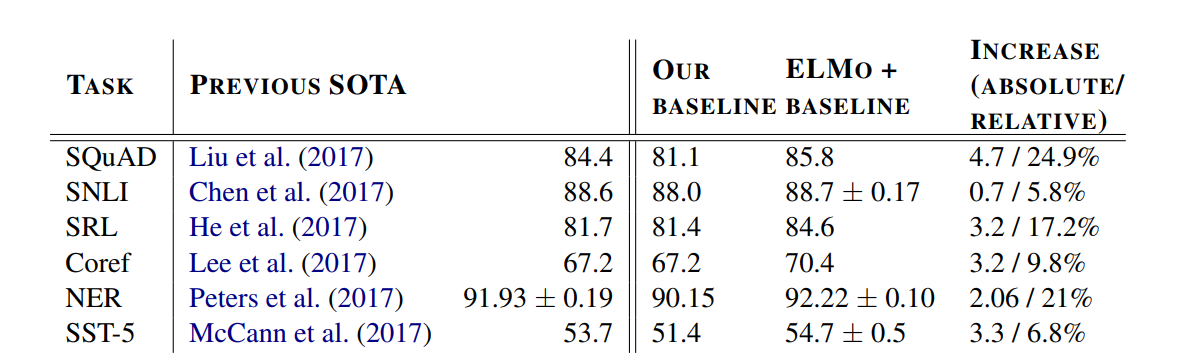
Word2Vec进阶 - ELMO – 潘登同学的NLP笔记 文章目录Word2Vec进阶 - ELMO -- 潘登同学的NLP笔记ELMO原理整体架构Char Encoder LayerBiLSTMELMO词向量实验结果总结ELMO
ELMo出自Allen研究所在NAACL2018会议上发表的一篇论文《Deep contextualized word representations》&…
机器学习——Word2Vec
参考资料:
https://zhuanlan.zhihu.com/p/114538417https://www.cnblogs.com/pinard/p/7243513.html
1 背景知识
1.1 统计语言模型
统计语言模型是基于语料库构建的概率模型,用来计算一个词串 W ( w 1 , w 2 , ⋯ , w T ) W(w_1,w_2,\cdots,w_T) W…

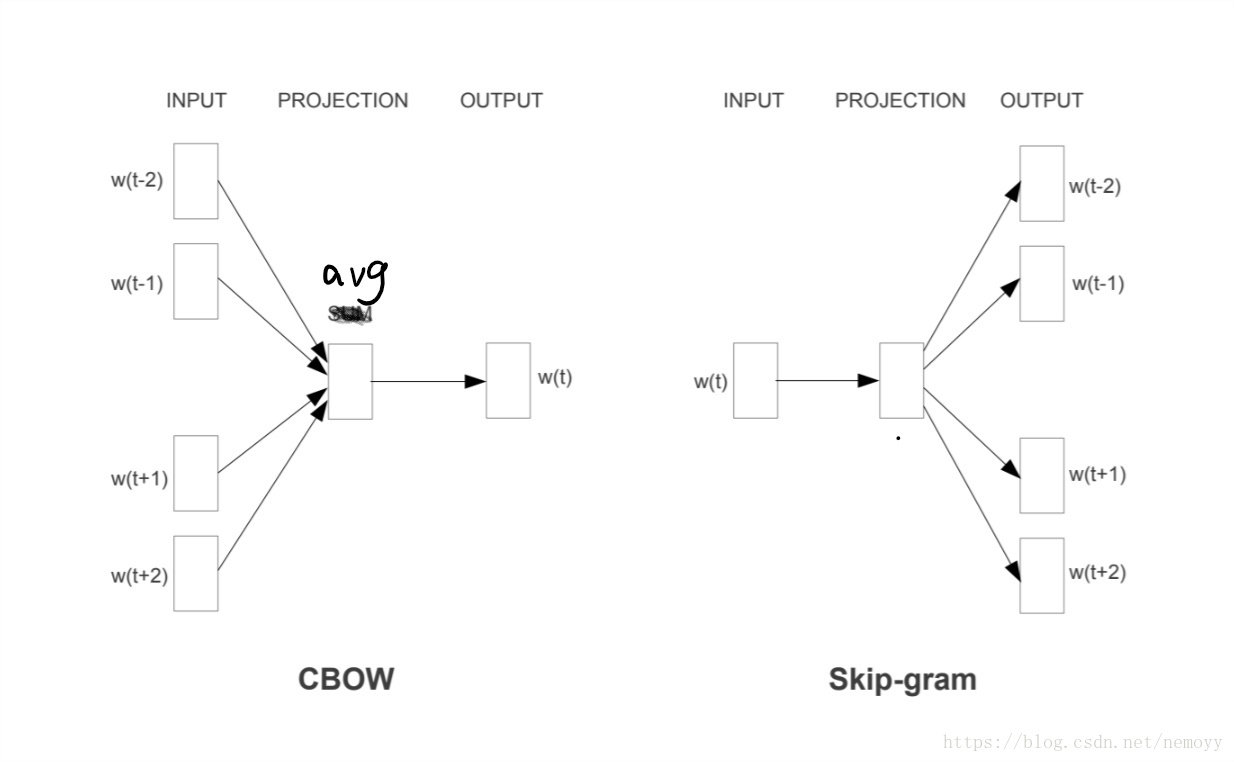
word2vec中的CBOW和Skip-gram
word2cev简单介绍
Word2Vec是一种用于学习词嵌入(word embeddings)的技术,旨在将单词映射到具有语义关联的连续向量空间。Word2Vec由Google的研究员Tomas Mikolov等人于2013年提出,它通过无监督学习从大规模文本语料库中学习词汇…

【机器学习】word2vec学习笔记(二):word2vec-tool
本文主要介绍Google官网提供的word2vec工具:word2vec,计算词的连续分布表示的工具。
本文并不涉及word2vec算法的原理与细节,只是简单的介绍了word2vec这个工具及一些在实践中的表现等。
word2vec工具提供了CBOW模型和skip-gram模型计算词的…
大语言模型LangChain本地知识库:向量数据库与文件处理技术的深度整合
文章目录 大语言模型LangChain本地知识库:向量数据库与文件处理技术的深度整合引言向量数据库在LangChain知识库中的应用文件处理技术在知识库中的角色向量数据库与文件处理技术的整合实践挑战与展望结论 大语言模型LangChain本地知识库:向量数据库与文件…
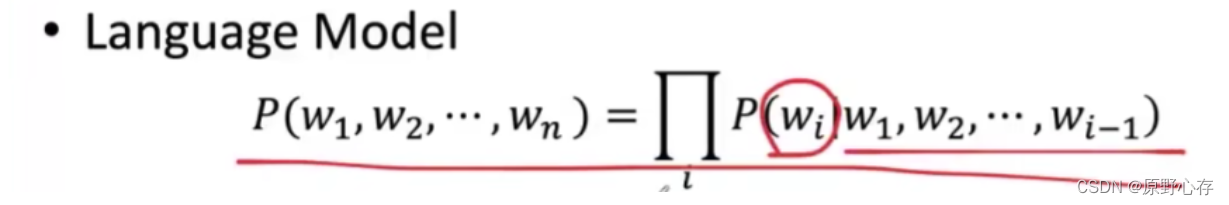

NLP模型(一)——word2vec实现
文章目录1. 整体思路2. 数据处理3. 数据准备4. 创建数据管道5. 构建模型6. 模型训练7. 加载模型得到词向量8. 总结前面我介绍了word2vec算法的两种实现算法,Skip−gramSkip-gramSkip−gram 以及 CBOWCBOWCBOW 算法,我认为理解一个算法最好的方法就是复现…

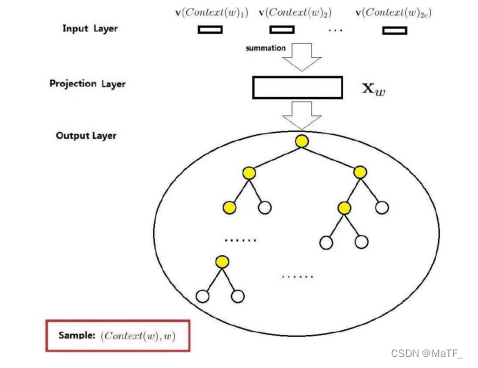
第三章 word2vec
目录3.1 基于推理的方法和神经网络3.1.1 基于计数的方法的问题3.1.2 基于推理的方法的概要3.1.3 神经网络中单词的处理方法3.2 简单的 word2vec3.2.1 CBOW模型的推理3.2.2 CBOW模型的学习3.2.3 word2vec的权重和分布式表示3.3 学习数据的准备3.3.1 上下文和目标词3.3.2 转化为o…
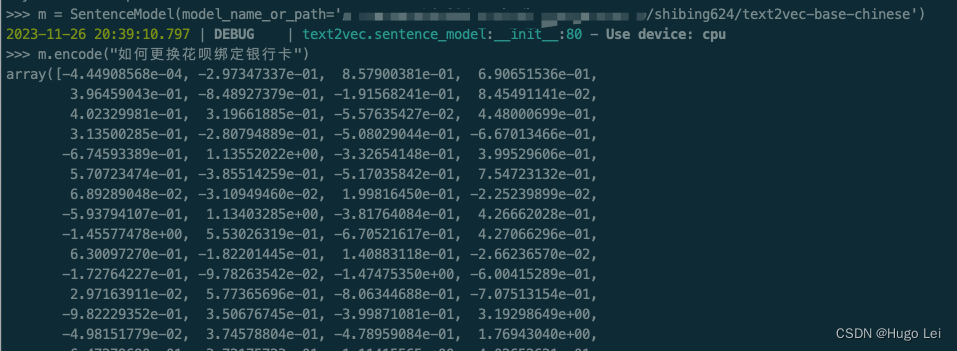
文档向量化工具(二):text2vec介绍
目录
前言
text2vec开源项目
核心能力
文本向量表示模型
本地试用
安装依赖
下载模型到本地(如果你的网络能直接从huggingface上拉取文件,可跳过)
运行试验代码 前言 在上一篇文章中介绍了,如何从不同格式的文件里提取…

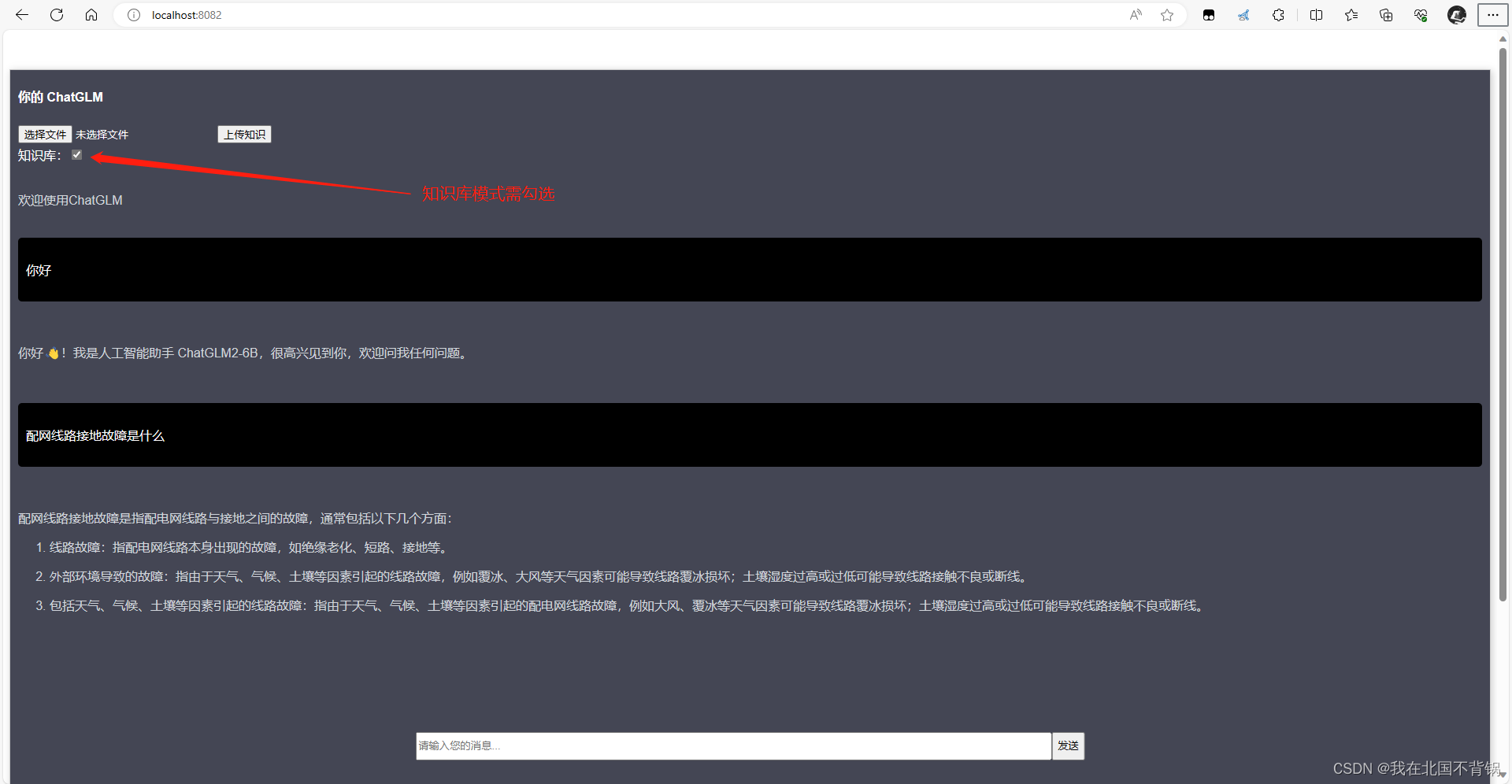
(提供数据集下载)基于大语言模型LangChain与ChatGLM3-6B本地知识库调优:数据集优化、参数调整、Prompt提示词优化实战
文章目录 (提供数据集下载)基于大语言模型LangChain与ChatGLM3-6B本地知识库调优:数据集优化、参数调整、提示词Prompt优化本地知识库目标操作步骤问答测试的预设问题原始数据情况数据集优化:预处理,先后准备了三份数据…
深度学习中的批归一化|深度学习
深度学习中的批归一化|深度学习
在进行神经网络训练的时候,除了一些优化算法外,还有其它的一些优化技术,这些技术并不是具体的算法,而是一些通用的技巧,其中批归一化就是常用的一个技巧。 批归一化是loffe等在2015年提…

大模型|基础_word2vec
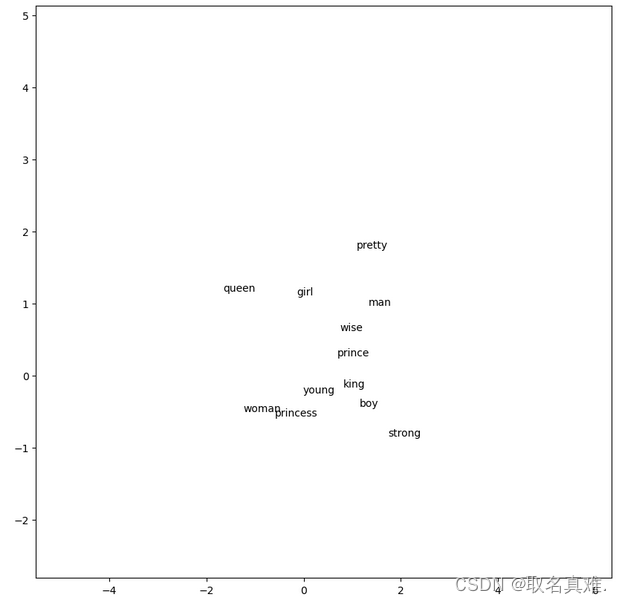
文章目录 Word2Vec词袋模型CBOW Continuous Bag-of-WordsContinuous Skip-Gram存在的问题解决方案 其他技巧 Word2Vec 将词转化为向量后,会发现king和queen的差别与man和woman的差别是类似的,而在几何空间上,这样的差别将会以平行的关系进行表…
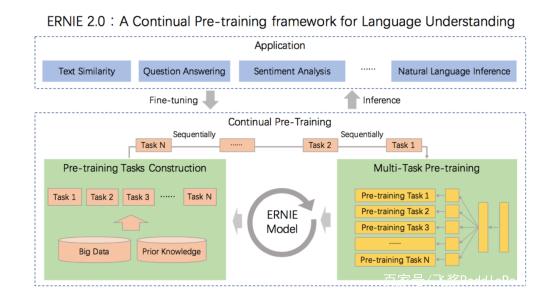
word2Vec进阶 -Bert
Word2Vec进阶 - Bert – 潘登同学的NLP笔记 文章目录Word2Vec进阶 - Bert -- 潘登同学的NLP笔记Bert介绍BERT的结构Bert的输入Bert的输出预训练任务Masked Language Model(MLM)Next Sentence Prediction(NSP)总结ERNIEERNIE2.0预训…
gensim库中word2vec的使用方式
gensim.models中的Word2Vec具体应用,里面的参数的含义以及一般取值
from gensim.models import Word2Vec# 示例文本
sentences [[this, is, a, sample, sentence],[another, example, sentence],[one, more, example]]# 训练 Word2Vec 模型
model Word2Vec(sente…

Word2Vec解释
Word2Vec解释
一、Word2Vec梗概
字面意思:即Word to Vector,由词到向量的方法。
专业解释:Word2Vec使用一层神经网络将one-hot(独热编码)形式的词向量映射到分布式形式的词向量。使用了Hierarchical softmax&#x…
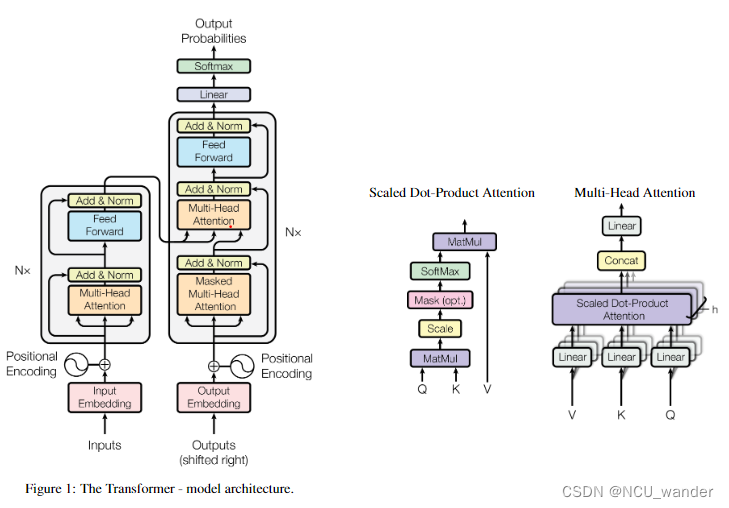
word2vec self-attention transformer diffusion的技术演变
这一段时间大模型的相关进展如火如荼,吸引了很多人的目光;本文从nlp领域入门的角度来总结相关的技术路线演变路线。
1、introduction
自然语言处理(Natural Language Processing),简称NLP。这个领域是通过统计学、数…

调用Gensim库训练Word2Vec模型
一、前期工作:
1. 安装Gensim库
pip install gensim
2.安装chardet库
pip install chardet 3. 对原始语料分词
选择《人民的名义》的小说原文作为语料,先采用jieba进行分词
import jieba
import jieba.analyse
import chardet
jieba.suggest_freq…
【NLP】如何实现快速加载gensim word2vec的预训练的词向量模型
1 问题
通过以下代码,实现加载word2vec词向量,每次加载都是几分钟,效率特别低。
from gensim.models import Word2Vec,KeyedVectors# 读取中文词向量模型(需要提前下载对应的词向量模型文件)
word2vec_model KeyedV…
基于word2vec+TextCNN 实现中文文本分类
基于word2vecTextCNN 作文本分类
一. 准备工作: 环境:python3.7torchGPU 数据集:网上下载的4分类中文文本,如下图: 模块使用:
import os
import jieba
import torch
import joblib
import torch.nn a…
深度学习:pytorch nn.Embedding详解
目录 1 nn.Embedding介绍
1.1 nn.Embedding作用
1.2 nn.Embedding函数描述
1.3 nn.Embedding词向量转化
2 nn.Embedding实战
2.1 embedding如何处理文本
2.2 embedding使用示例
2.3 nn.Embedding的可学习性 1 nn.Embedding介绍
1.1 nn.Embedding作用
nn.Embedding是Py…

【Gensim概念】01/3 NLP玩转 word2vec
第一部分 词法
一、说明 Gensim是一种Python库,用于从文档集合中提取语义主题、建立文档相似性模型和进行向量空间建模。它提供了一系列用于处理文本数据的算法和工具,包括主题建模、相似性计算、文本分类、聚类等。在人工智能和自然语言处理领域&…
Python实现Word2vec学习笔记
Python实现Word2vec学习笔记 参考: 中文word2vec的python实现 python初步实现word2vec 中英文维基百科语料上的Word2Vec实验
GitHub代码地址
1 文件目录结构:
[.../vord2vec]$ls
data model_train.py word2vec_test.py word_cut.py
[.../vord2…
Word2Vec的CBOW模型
Word2Vec中的CBOW(Continuous Bag of Words)模型是一种用于学习词向量的神经网络模型。CBOW的核心思想是根据上下文中的周围单词来预测目标单词。
例如,对于句子“The cat climbed up the tree”,如果窗口大小为5,那么…
使用word2vec+tensorflow自然语言处理NLP
目录 介绍: 搭建上下文或预测目标词来学习词向量
建模1:
建模2:
预测:
介绍: Word2Vec是一种用于将文本转换为向量表示的技术。它是由谷歌团队于2013年提出的一种神经网络模型。Word2Vec可以将单词表示为高维空间…
【Gensim概念】02/3 NLP玩转 word2vec
第二部分 句法 六、句法模型(类对象和参数)
6.1 数据集的句子查看
classgensim.models.word2vec.BrownCorpus(dirname) Bases: object 迭代句子 Brown corpus (part of NLTK data).
6.2 数据集的句子和gram
classgensim.models.word2vec.Heapitem(c…

数据挖掘实战-基于word2vec的短文本情感分析
🤵♂️ 个人主页:艾派森的个人主页 ✍🏻作者简介:Python学习者 🐋 希望大家多多支持,我们一起进步!😄 如果文章对你有帮助的话, 欢迎评论 💬点赞Ǵ…
如何用词向量做文本分类(embedding+cnn)
1、数据简介
本文使用的数据集是著名的”20 Newsgroup dataset”。该数据集共有20种新闻文本数据,我们将实现对该数据集的文本分类任务。数据集的说明和下载请参考(http://www.cs.cmu.edu/afs/cs.cmu.edu/project/theo-20/www/data/news20.html…
FAISS+bge-large-zh在大语言模型LangChain本地知识库中的作用、原理与实践
文章目录 FAISSbge-large-zh在大语言模型LangChain本地知识库中的作用、原理与实践引言FAISS与bge-large-zh简介FAISS原理bge-large-zh原理 FAISSbge-large-zh在LangChain本地知识库中的作用提高检索效率增强语义理解能力支持大规模数据处理 实践数据准备与处理FAISS索引构建与…

NLP 使用Word2vec实现文本分类
🍨 本文为[🔗365天深度学习训练营学习记录博客 🍦 参考文章:365天深度学习训练营 🍖 原作者:[K同学啊 | 接辅导、项目定制]\n🚀 文章来源:[K同学的学习圈子](https://www.yuque.com/…

Word2Vec进阶 -GPT2
Word2Vec进阶 - GPT2 – 潘登同学的NLP笔记 文章目录Word2Vec进阶 - GPT2 -- 潘登同学的NLP笔记GPT2网络结构预训练任务机器翻译自动摘要生成阅读理解Zero-shot,One-shot,Few-shot问题来了Bert与GPT2的区别Bert与GPT2的区别GPT2网络结构
Bert是用了Transformer的Encoder层&…
ELMo模型、word2vec、独热编码(one-hot编码)的优缺点进行对比
下面是对ELMo模型、word2vec和独热编码(one-hot编码)的优缺点进行对比:
独热编码(One-hot Encoding): 优点:
简单,易于理解。适用于词汇表较小的场景。
缺点:
高维度…

【机器学习】word2vec学习笔记(一):word2vec源码解析
0. word2vec地址
官网地址:https://code.google.com/archive/p/word2vec/GitHub地址:https://github.com/tmikolov/word2vec
1. word2vec算法原理
本模块主要介绍word2vec的算法原理。
word2vec用到了两个重要的模型:CBOW模型和Skip-gram模…

Speech and Language Processing之word2vec
1、介绍 事实证明,在每一个NLP任务中,密集向量都比稀疏向量工作得更好。虽然我们不能完全理解其中的所有原因,但我们有一些直觉。首先,密集向量可以更成功地作为特征包含在机器学习系统中;例如,如果我们使用100维…
【Gensim概念】03/3 NLP玩转 word2vec
第三部分 对象函数 八 word2vec对象函数 该对象本质上包含单词和嵌入之间的映射。训练后,可以直接使用它以各种方式查询这些嵌入。有关示例,请参阅模块级别文档字符串。
类型
KeyedVectors
1) add_lifecycle_event(event_name, log_level2…
word2vec原理
1.背景 2013年,Google开源了一款用于词向量计算的工具—word2vec,引起了工业界和学术界的关注。首先,word2vec可以在百万数量级的词典和上亿的数据集上进行高效地训练;其次,该工具得到的训练结果——词向量(word embed…
【NLP入门教程】十三、Word2Vec保姆教程
Word2Vec
概述
Word2Vec是一种广泛使用的词嵌入技术,它能够将单词表示为连续向量,将语义上相似的词映射到相近的向量空间。Word2Vec模型是由Tomas Mikolov等人于2013年提出的,它基于分布式假设,即上下文相似的单词具有相似的含义。
Word2Vec模型有两个主要的实现算法:连…
Word2vec原理+实战学习笔记(一)
来源:投稿 作者:阿克西 编辑:学姐 视频链接:https://ai.deepshare.net/detail/p_5ee62f90022ee_zFpnlHXA/6 文章标题: Efficient Estimation of Word Representations in Vector Space 基于向量空间中词表示的有效估计…

读《word2vec中的数学原理详解》的一点理解
这里添加一个链接,很好的一篇word2vec的文章,叫做《word2vec中的数学原理详解》
点击打开链接
本人上传了在知网看到的一篇 language model RNN的文章,因为自己也是新手,所以上传,如果需要,可以到我的下…
论文笔记--Enriching Word Vectors with Subword Information
论文笔记--Enriching Word Vectors with Subword Information 1. 文章简介2. 文章概括3 文章重点技术3.1 FastText模型3.2 Subword unit 4. 文章亮点5. 原文传送门6. References 1. 文章简介
标题:Enriching Word Vectors with Subword Information作者:…

深度学习之——word2vec
1. 文本表示:从one-hot到word2vec 文本表示的意思是把字词处理成向量或矩阵,以便计算机能进行处理。文本表示是自然语言处理的开始环节。
文本表示按照细粒度划分,一般可分为字级别、词语级别和句子级别的文本表示。
文本表示分为离散表示和…

Word2vec和embedding 非底层算法原理讲解
网上关于二者的信息真的是多如牛毛,参差不齐。 本文不对算法细节进行讲解推导,不从零开始讲二者含义,主要记录些学习中出现的问题。 建议先看完基础知识再浏览,欢迎大家留言指出错误或留下你的疑问。 先贴几个不错的链接
word2ve…
![[学习笔记]词向量模型-Word2vec](https://img-blog.csdnimg.cn/855a9cd0efea453dbf95f9ec87210082.png)
[学习笔记]词向量模型-Word2vec
参考资料: 【word2vec词向量模型】原理详解代码实现 NLP自然语言处理的经典模型Word2vec
论文背景知识
词的表示方法
One-hot Representation:独热表示 简单,但词越多,向量越长。且无法表示词与词之间的关系。 论文储备知识-pr…
word2vec,BERT,GPT相关概念
词嵌入(Word Embeddings)
词嵌入通常是针对单个词元(如单词、字符或子词)的。然而,OpenAI 使用的是预训练的 Transformer 模型(如 GPT 和 BERT),这些模型不仅可以为单个词元生成嵌入…

word2vec的原理及实现(附github代码)
目录
一、word2vec原理
二、word2vec代码实现
(1)获取文本语料
(2)载入数据,训练并保存模型
① # 输出日志信息
② # 将语料保存在sentence中
③ # 生成词向量空间模型
④ # 保存模型
(3&…
M3EChatGLM向量化构建本地知识库
M3E&ChatGLM向量化构建本地知识库 整体步骤向量数据库向量数据库简介主流数据库Milvus部署 文本向量化M3E介绍模型对比M3E使用向量数据存储 基于本地知识库的问答问句向量化向量搜索请求ChatGLM问答测试 整体步骤
向量化:首先,你需要将语言模型的数…
工智能基础知识总结--词嵌入之Word2Vec
词嵌入要解决什么问题 在自然语言系统中,词被看作最为基本的单元,如何将词进行向量化表示是一个很基本的问题,词嵌入(word embedding)就是把词映射为低维实数域向量的技术。 下面先介绍几种词的离散表示技术,然后总结其缺点,最后介绍词的分布式表示及其代表技术(word2v…
word2vec的算法原理(不用开源包,python实现)
看了很多关于word2vec的算法原理的介绍文章,看明白了,但依然有点不深刻。
以下是python直接实现的word2vec的算法,简单明了,读完就懂了
import numpy as npdef tokenize(text):return text.lower().split()def generate_word_pa…

深入理解Word Embeddings:Word2Vec技术与应用
目录 前言1 Word2Vec概述2 CBOW模型2.1 CBOW模型简介2.2 基于词袋(bag of word)的假设2.3 One-hot向量编码2.4 分类问题 3 Skip-gram模型3.1 Skip-gram模型简介3.2 目标词预测上下文3.3 词语关联性的捕捉 4 优化Word2Vec模型的方法4.1 负采样和分层softm…
Word2Vector介绍
Word2Vector 2013 word2vec也叫word embeddings,中文名“词向量”,google开源的一款用于词向量计算的工具,作用就是将自然语言中的字词转为计算机可以理解的稠密向量。在word2vec出现之前,自然语言处理经常把字词转为离散的单独的…
word2vec 理解
word2vec是google在2013年推出的一个NLP工具,它的特点是将所有的词向量化,这样词与词之间就可以定量的去度量他们之间的关系,挖掘词之间的联系。广泛的运用到自然语言中 详情文章 https://zhuanlan.zhihu.com/p/114538417
word2vec原理(一) …
基于Word2vec词聚类的关键词实现
一.基于Word2vec词聚类的关键词步骤
基于Word2Vec的词聚类关键词提取包括以下步骤:
1.准备文本数据:收集或准备文本数据,可以是单一文档或文档集合,涵盖关键词提取的领域。2.文本预处理:清洗文本数据,去除…

大语言模型系列-word2vec
文章目录 前言一、word2vec的网络结构和流程1.Skip-Gram模型2.CBOW模型 二、word2vec的训练机制1. Hierarchical softmax2. Negative Sampling 总结 前言
在前文大语言模型系列-总述已经提到传统NLP的一般流程:
创建语料库 > 数据预处理 > 分词向量化 > …
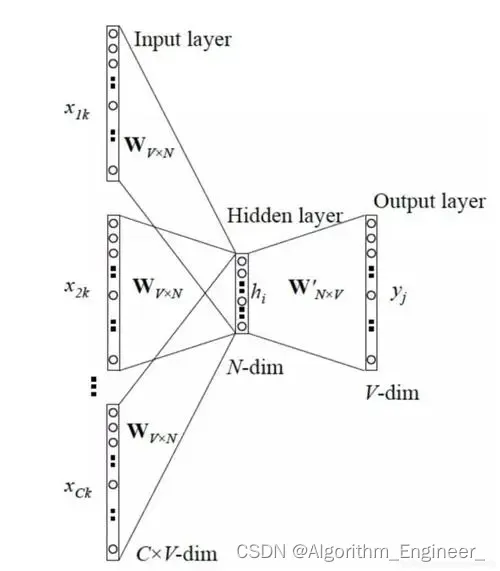
中文词向量训练-案例分析
1 数据预处理,解析XML文件并分词
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# process_wiki_data.py 用于解析XML,将XML的wiki数据转换为text格式
import logging
import os.path
import sys
from gensim.corpora import WikiCorpus
import jieba…

词向量模型 Word2Vec 2022-1-18
人工智能基础总目录 词向量模型一 One hot编码缺点PCA/SVD后的问题二 Word2vec1.1 目标函数2.1 主流计算方法1 Skip gram2 CBOW2.2 计算方面的优化方法1 Tree softmax2 Negative Sampling (NEG)三 Glove 模型四 句子向量Word embedding 是自然语言处理中…

word2vec及其优化
1.算法背景:
(1)N-gram:n-1阶的Markov模型,认为一个词出现的概率只与前面n-1个词相关;统计预料中各种词串(实际应用中最多采用n3的词串长度)的出现次数,并做平滑处理&am…
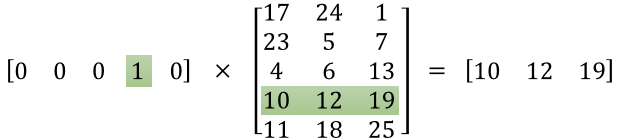
Word2vec之skip-gram模型理解
一、Word2vec背景
传统的词向量一般使用one-hot表示,但会面临两个问题: (1)高维稀疏的向量带来计算成本 (2)不同的词向量无法正交,无法衡量词之间的相似度。 word2vec是一个将词进行低维稠密向…
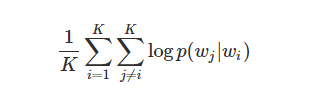
item2vec--word2vec在推荐领域的使用
一:绪论
在word2vec诞生以后,embedding的思想迅速从自然语言处理领域扩大到各个领域,推荐系统也不例外,既然word2vec可以对词序列中的词进行embedding,那么也可以对用户购买序列中的一个商品也应该存在相应的embeddin…

GraphEmbedding - DeepWalk 图文详解
一.引言
上一篇文章讲到了如何使用 networkx 获取图 ,通过networkx 获得的图我们可以通过获取节点的邻居开始随机游走,从而获得游走序列,进而结合 word2vec 进行节点向量化操作。 二.DeepWalk 原理
1.获得关注关系图
通过节点之间的关系生…

word2vec之CBOW模型与skip-gram模型
在对自然语言进行处理时,首先需要面对文本单元表示问题。单词(words)作为常考虑的最小文本单元,因而,如何将单词表示成恰当的词向量(word vector)成为了研究者们研究的重点。最简单直观的方法是…
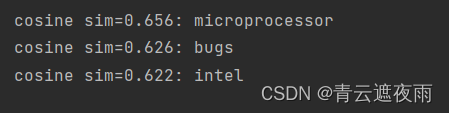
自然语言处理(三):基于跳元模型的word2vec实现
跳元模型
回顾一下第一节讲过的跳元模型
跳元模型(Skip-gram Model)是一种用于学习词向量的模型,属于Word2Vec算法中的一种。它的目标是通过给定一个中心词语来预测其周围的上下文词语。
这节我们以跳元模型为例,讲解word2vec的…

genism word2vec方法
文章目录 概述使用示例模型的保存与使用训练参数详解([原链接](https://blog.csdn.net/weixin_44852067/article/details/130221655))语料库训练 概述
word2vec是按句子来处理的Sentences(句子们)
使用示例
from gensim.models import Word2Vec
#sent…

负采样:如何高效训练词向量
Negative Sampling
1.何为负采样
负采样是一种用于训练词嵌入模型的采样方法,特别适用于处理大规模词汇表的情况。负采样的目标是降低计算成本并改善模型的性能,同时有效地训练词向量。
2.为什么需要负采样
在传统的词嵌入模型中,如Word…

Word2Vec原理简单解析
前言
词的向量化就是将自然语言中的词语映射成是一个实数向量,用于对自然语言建模,比如进行情感分析、语义分析等自然语言处理任务。下面介绍比较主流的两种词语向量化的方式:
第一种即One-Hot编码
是一种基于词袋(bag of words)的编码…

理解Word2Vec模型
Word2Vec的理解首言一、SG模型中的名词解释1.1. 独热码1.2 建模过程二、SG模型的损失函数2.1表达形式12.2 表达形式22.3 softmax函数三、模型的计算过程3.1 数据的表示3.2 隐层3.3 输出层3.4 SG模型的计算过程3.5 SG模型参数θ\thetaθ确定的数学证明四、高级词向量表示4.1常规…
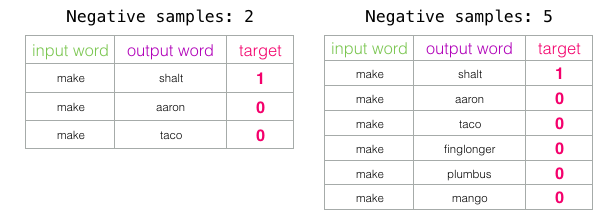
图解Word2vec
作者: 龙心尘 时间:2019年4月 出处:https://blog.csdn.net/longxinchen_ml/article/details/89077048
审校:龙心尘 作者:Jay Alammar 编译:张秋玥、毅航、高延 嵌入(embedding)是机…

Word2Vec浅谈
论文地址:Efficient Estimation of Word Representations in Vector Space
word2vec是Google团队在2013年发表的一篇paper,当时一经问世直接将NLP领域带到了一个新的高度,在2018年bert被提出之前,word2vec一直是NLP算法工程师追捧…
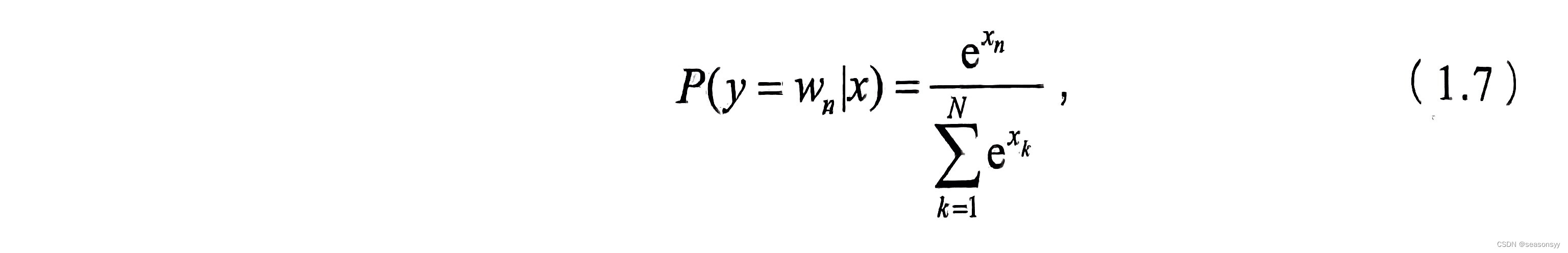
1.4 Word2Vec是如何工作的? Word2Vec与LDA 的区别和联系?
1.4 Word2Vec:词嵌入模型之一
场景描述
谷歌2013年提出的Word2Vec是目前最常用的词嵌入模型之一。
Word2Vec实际是一种浅层的神经网络模型,它有两种网络结构,分别是CBOW(Continues Bag of Words)和Skip-gram。 知识点
Word2Vec,隐狄利克雷模型(LDA),…
大语言模型微调相关的finetuning、CE Loss、RLHF如何配合工作
文章目录 大语言模型微调相关的finetuning、CE Loss、RLHF如何配合工作概念定义虽然有点啰嗦,但是值得反复强化概念 RAG、Agent、Finetuning之间的关系RAG、Agent、Finetuning各自的技术方法步骤流程示例代码 pytorch 抱抱脸Hugging Face基于预训练模型做微调基于预…
【报错解决】TypeError: __init__() got an unexpected keyword argument ‘size‘
报错描述
我在使用Doc2vec训练模型时,遇到了这一报错,相应的代码及报错信息如下所示:
#代码model Doc2Vec(x_train, min_count5, window5, sizesize, sample1e-4, negative5,workersmultiprocessing.cpu_count())#报错信息TypeError: __in…
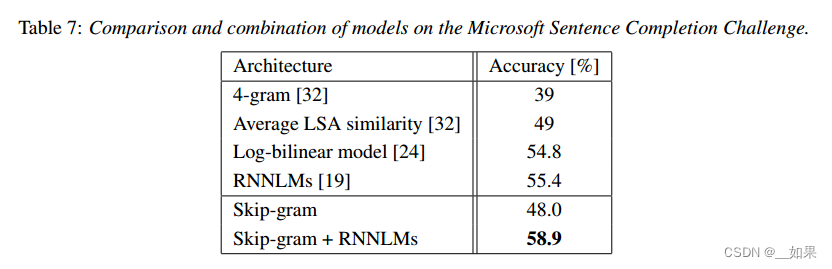
论文精读--word2vec
word2vec从大量文本语料中以无监督方式学习语义知识,是用来生成词向量的工具
把文本分散嵌入到另一个离散空间,称作分布式表示,又称为词嵌入(word embedding)或词向量
Abstract We propose two novel model architec…

FastEI论文阅读
前言 研究FastEI有很长时间了,现在来总结一下,梳理一下认知。论文地址:https://www.nature.com/articles/s41467-023-39279-7,Github项目地址:https://github.com/Qiong-Yang/FastEI。
概要 这篇文章做的工作是小分子…
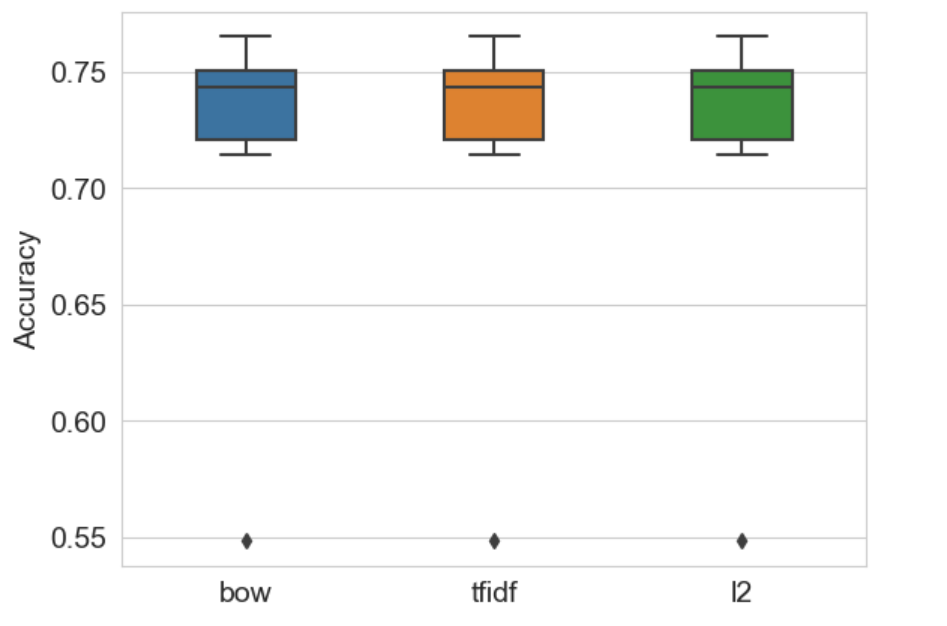
《精通特征工程》学习笔记(3):特征缩放的效果-从词袋到tf-idf
1.TF-IDF原理
tf-idf 是在词袋方法基础上的一种简单扩展,它表示词频 - 逆文档频率。tf-idf 计算的不是数据集中每个单词在每个文档中的原本计数,而是一个归一化的计数,其中每个单词的计数要除以这个单词出现在其中的文档数量。
词袋bow(w, …
word2vec 精确率是如何计算的?
这里提到的精确率指的是word2vec模型使用Skip-gram或CBOW算法训练得到的词向量在单词预测任务中的准确率。具体而言,这个数值评估了word2vec模型对于给定上下文单词后正确预测目标单词的能力。
例如,给定这样一段文本:
“the cat sat on th…
中文分词库:jieba的词性对照表
jieba词性对照表
字母词性a形容词ad副形词ag形容词性语素an名形词b区别词c连词d副词dg副词素e叹词f方位词g语素h前接成分i成语j简称略称k后接成分l习用语m数词mq数量词n名词ng名词性语素nr人名ns地名nt机构团体名nz其他专名o拟声词p介词q量词r代词rg代词性语素rr人称代词rz指示…
『NLP学习笔记』图解Word2vec(The Illustrated Word2vec)
图解Word2vec(The Illustrated Word2vec) 文章目录 一. 词嵌入(word embedding)1.1. 个性嵌入:你是什么样的人?1.2. 词嵌入1.3. 类比1.4. 语言模型1.5. 语言模型训练1.6. 顾及两头(上下文)1.7. Skip-gram模型1.8. 重新审视训练过程1.9. 负例采样1.10. 基于负例采样的Skip…
一文了解Word2vec 阐述训练流程
一文了解Word2vec 阐述训练流程 个性嵌入(Personality Embeddings) 词嵌入(Word Embeddings) 嵌入向量效果分析 语言模型 模型介绍 模型训练 Word2vec训练方法 CBOW方法 Skip-gram方法 CBOW方法与Skip-gram方法总结 重构…
word2vec: 理解nnlm, cbow, skip-gram
word2vec 论文笔记
1 word rep
怎么表示词的意思? 传统的想法有查字典. 近义词,缺点:主观,费人力, 难记算相似性 one-hot 缺点:维度灾难,正交,无法计算similarity. 那么,通过借鉴近义词,学习将similarity编码到词向量中去.
1.1 one-hot
n-gram language model见我之前写…

极客时间: 用 Word2Vec, LangChain, Gemma 模拟全本地检索增强生成(RAG)
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…

机器不学习:word2vec是如何得到词向量的?
转自:http://baijiahao.baidu.com/s?id1591743538838829040&wfrspider&forpc机器不学习 jqbxx.com -机器学习、深度学习好网站word2vec是如何得到词向量的?这个问题比较大。从头开始讲的话,首先有了文本语料库,你需要对语…
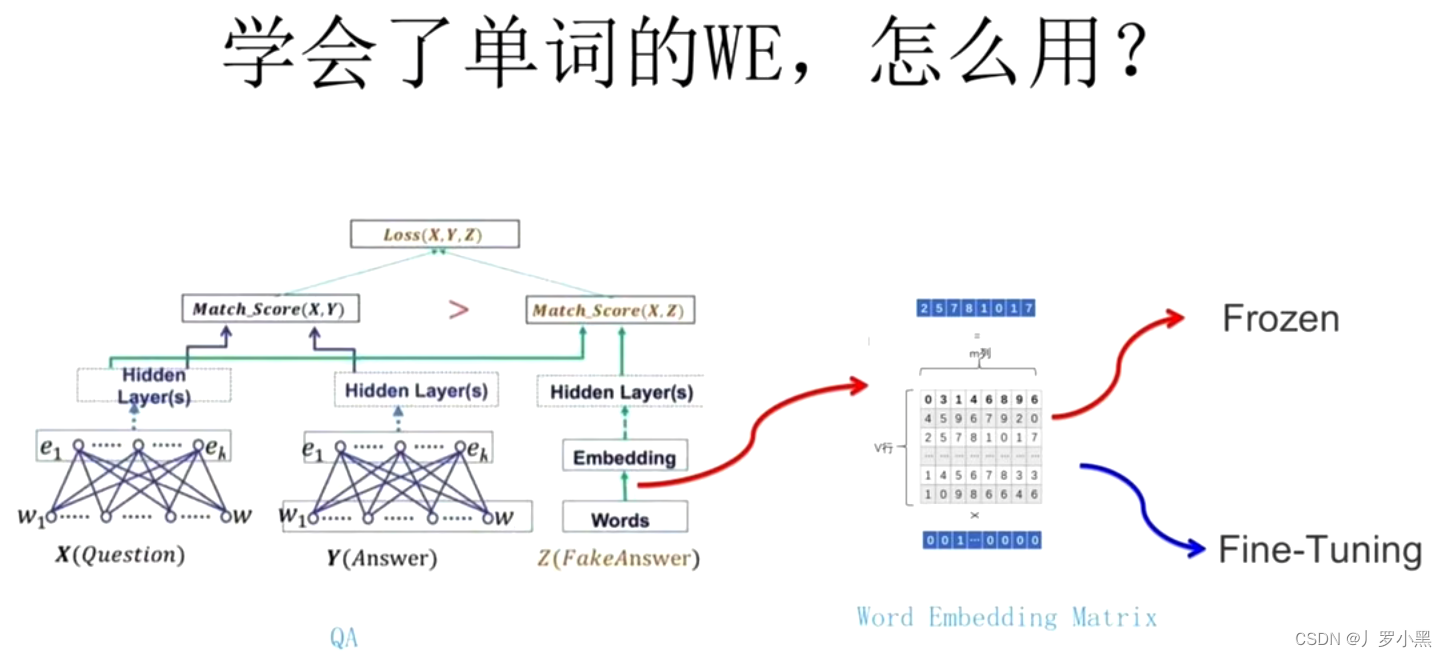
Transformer的前世今生 day03(Word2Vec、如何使用在下游任务中)
前情回顾
由上一节,我们可以得到: 任何一个独热编码的词都可以通过Q矩阵得到一个词向量,而词向量有两个优点: 可以改变输入的维度(原来是很大的独热编码,但是我们经过一个Q矩阵后,维度就可以控…
深度学习(二):详解Word2Vec,从统计语言模型,神经网络语言模型(NNLM)到Hierarchical Softmax、Negative Sampling的CBOW和Skip gram
首先计算机只认识01数字,要对文本进行处理就需要将单词进行向量化
单词的向量化表示方法 独热表示one-hot
最早对于单词向量化使用的是独热表示。每个单词对应一个向量,这个向量维度等于词汇表的大小,也就是说我有一个词汇表,里…
让机器理解语言,从字词开始,逐步发展到句子和文档理解:独热编码、word2vec、词义搜索、句意表示、暴力加算力
让机器理解语言,从字词开始,逐步发展到句子和文档理解:独热编码、词嵌入、word2vec、词义搜索、句意表示、暴力加算力 独热编码:分类 二进制特征Word2Vec 词嵌入: 用低维表示 用嵌入学习 用上下文信息Skip-gram 跳字…
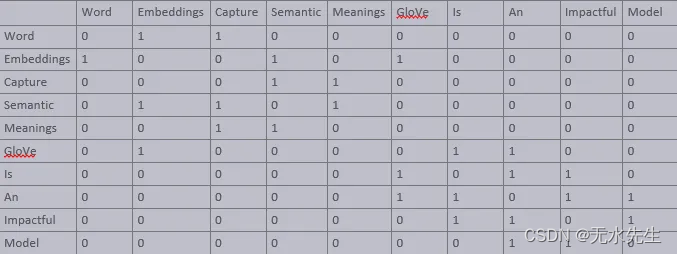
【文本到上下文 #6】Word2Vec、GloVe 和 FastText
一、说明 欢迎来到“文本到上下文”博客的第 6 个系列。到目前为止,我们已经探索了自然语言处理的基础知识、应用和挑战。我们深入研究了标记化、文本清理、停用词、词干提取、词形还原、词性标记和命名实体识别。我们的探索包括文本表示技术,如词袋、TF…
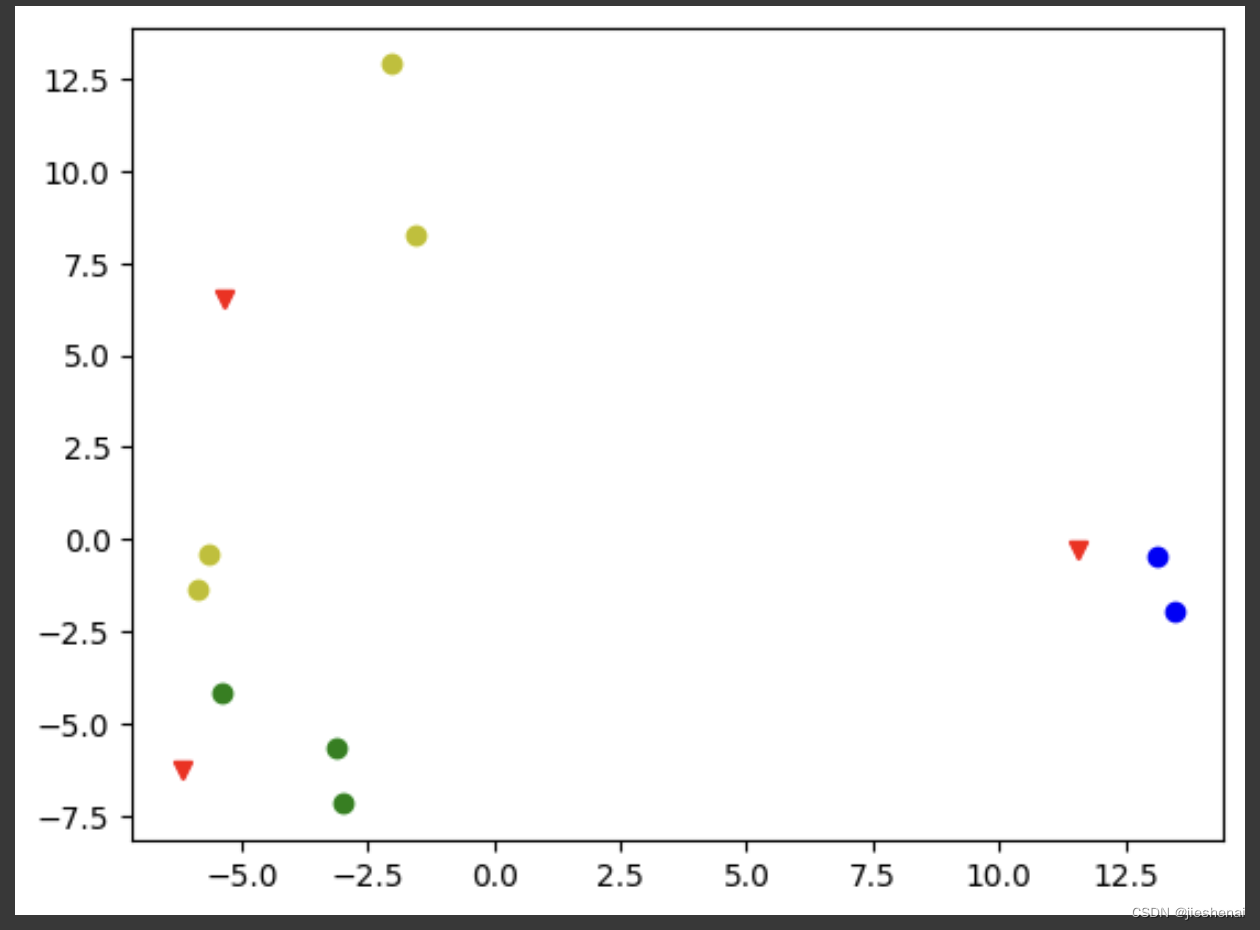
基于word2vec 和 fast-pytorch-kmeans 的文本聚类实现,利用GPU加速提高聚类速度
文章目录 简介GPU加速 代码实现kmeans聚类结果kmeans 绘图函数相关资料参考 简介
本文使用text2vec模型,把文本转成向量。使用text2vec提供的训练好的模型权重进行文本编码,不重新训练word2vec模型。 直接用训练好的模型权重,方便又快捷 完整…
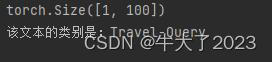
NLP实战:使用Word2vec实现文本分类
目录
一、数据预处理
1、加载数据
2. 构建词典
3.生成数据批次和迭代器
二、模型构建
1.搭建模型
2.初始化模型
3.定义训练与评估函数
三、训练模型
1. 拆分数据集并运行模型
2. 测试指定数据 🍨 本文为[🔗365天深度学习训练营]内部限免文章&…

word2vec两种优化方式的联系和区别
总结不易,请大力点赞,感谢
上一个文章,Word2vec-负采样/霍夫曼之后模型是否等价-绝对干货是字节的面试真题,建议朋友们多看几遍,有问题及时沟通。
私下有几个朋友看完之后还是有点懵,又问了一下具体细节。…
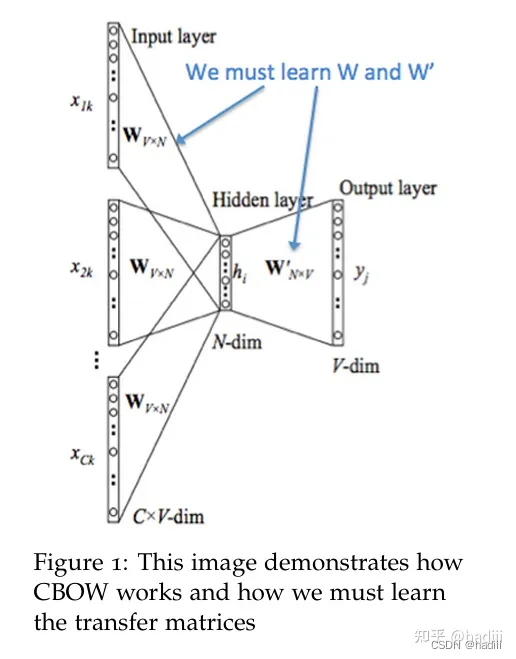
Word2Vec详解: CBOW Skip-gram和负采样
Word2Vec: CBOW & Skip-gram 如果是拿一个词语的上下文作为输入,来预测这个词语本身,则是 CBOW 模型。 而如果是用一个词语作为输入,来预测它周围的上下文,那这个模型叫做 Skip-gram 模型。 CBOW 模型
连续词袋模…
使用 PyTorch 实现 Word2Vec 中Skip-gram 模型
首先创建了一个使用 Word2VecDataset 类自定义的数据集,用于生成训练数据。然后,定义了 Skip-gram 模型,并使用交叉熵损失函数和 Adam 优化器进行训练。
在每个训练周期中,遍历数据加载器,对每个批次进行前向传播、计…
聊一下Word2vec-训练优化篇
Word2vec 涉及到两种优化方式,一种是负采样,一种是层序Softmax
先谈一下负采样,以跳字模型为例。中心词生成背景词可以由两个相互独立事件的联合组成来近似(引自李沐大神的讲解)。
第一个事件是,中心词和…

【Spark-ML源码解析】Word2Vec
前言
在阅读源码之前,需要了解Spark机器学习Pipline的概念。 相关阅读:SparkMLlib之Pipeline介绍及其应用 这里比较核心的两个概念是:Transformer和Estimator。 Transformer包括特征转换和学习后的模型两种情况,用来将一个DataFr…
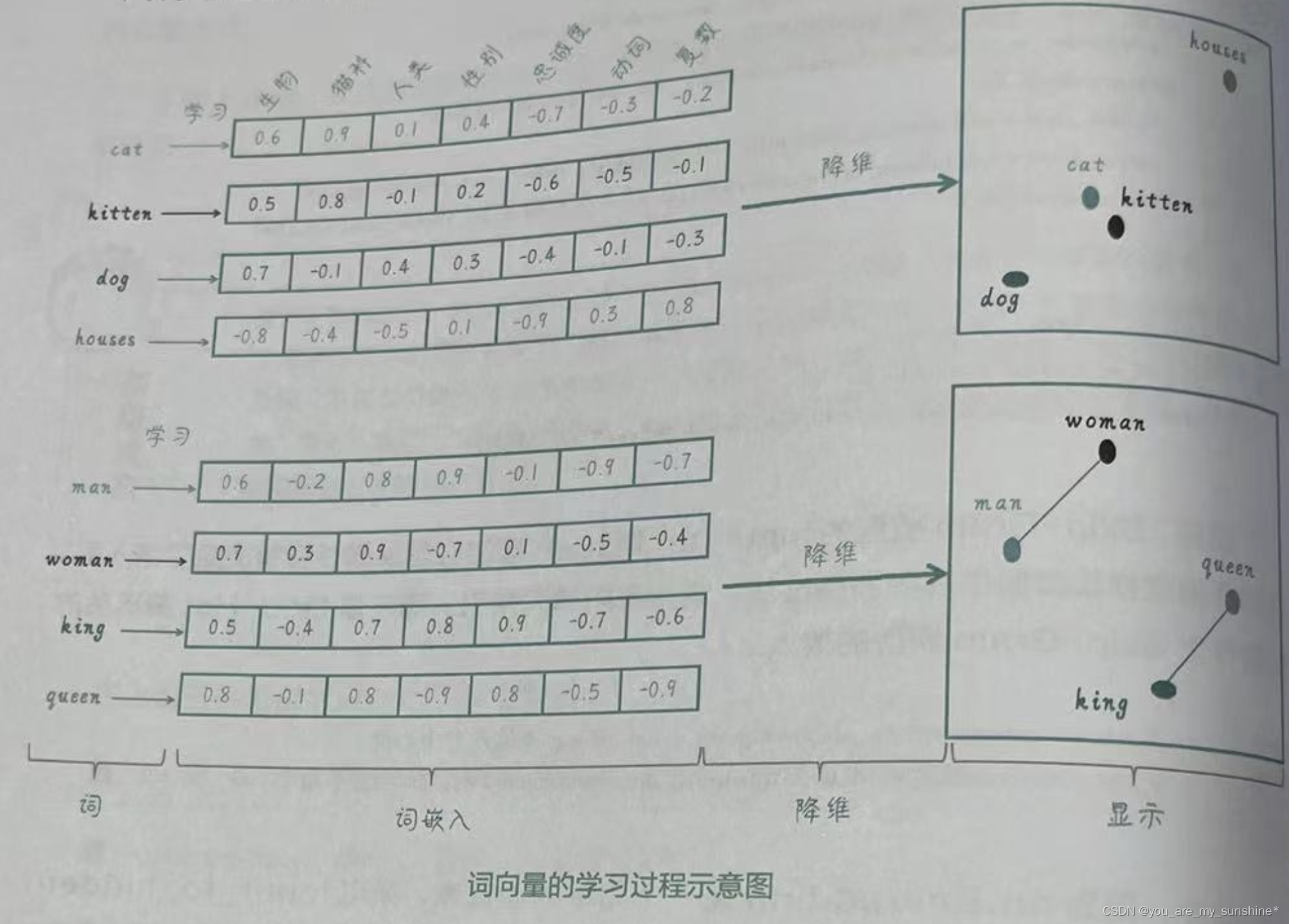
NLP_词的向量表示Word2Vec 和 Embedding
文章目录 词向量Word2Vec:CBOW模型和Skip-Gram模型通过nn.Embedding来实现词嵌入Word2Vec小结 词向量
下面这张图就形象地呈现了词向量的内涵:把词转化为向量,从而捕捉词与词之间的语义和句法关系,使得具有相似含义或相关性的词语在向量空间…

深兰科技陈海波出席CTDC2024第五届首席技术官领袖峰会:“民主化AI”的到来势如破竹
1月26日,CTDC 2024 第五届首席技术官领袖峰会暨出海创新峰会在上海举行。深兰科技创始人、董事长陈海波受邀出席了本届会议,并作为首个演讲嘉宾做了题为“前AGI时代的生产力革命范式”的行业分享。 作为国内顶级前瞻性技术峰会,CTDC首席技术官…
Word2Vec的原理是什么,如何用训练Word2Vec
Word2Vec是一种基于神经网络的词向量生成模型,通过训练预测上下文单词或中心单词来生成词向量。它包含两种不同的架构:跳字模型(Skip-gram)和连续词袋模型(Continuous Bag-of-Words, CBOW),它们…
机器学习-基于Word2vec搜狐新闻文本分类实验
机器学习-基于Word2vec搜狐新闻文本分类实验
实验介绍
Word2vec是一群用来产生词向量的相关模型,由Google公司在2013年开放。Word2vec可以根据给定的语料库,通过优化后的训练模型快速有效地将一个词语表达成向量形式,为自然语言处理领域的应…
【机器学习】word2vec学习笔记(三):word2vec源码注释
1. word2vec地址
官网地址:https://code.google.com/archive/p/word2vec/GitHub地址:https://github.com/tmikolov/word2vec
2. word2vec源码注释
// Copyright 2013 Google Inc. All Rights Reserved.
//
// Licensed under the Apache License, Ve…

word2vec的算法思想详解(cbow+skipgram+negative sampling))
参考: https://easyai.tech/ai-definition/word2vec/ https://jalammar.github.io/illustrated-word2vec/
Word2vec 是 Word Embedding 词嵌入的方法之一。
Word Embedding 就是将「不可计算」「非结构化」的词转化为「可计算」「结构化」的向量。 Word2vec 有 2 …

【自然语言处理】 - 作业1: Word2Vec及TransE实现
课程链接: 清华大学驭风计划
代码仓库:Victor94-king/MachineLearning: MachineLearning basic introduction (github.com) 驭风计划是由清华大学老师教授的,其分为四门课,包括: 机器学习(张敏教授) , 深度学习(胡晓林教授), 计算…
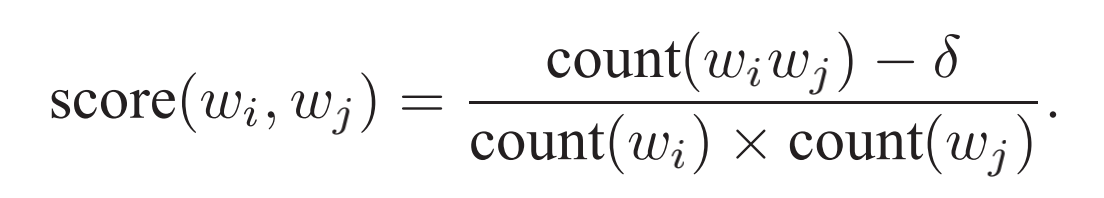
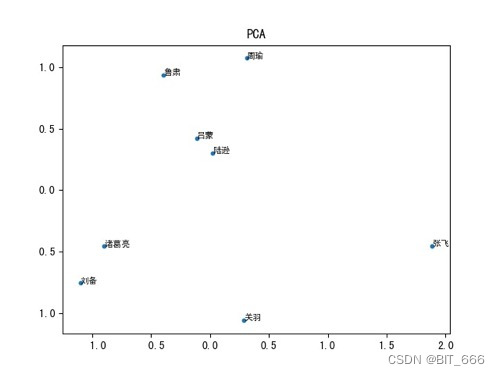
深度学习 - 38.Gensim Word2Vec 实践
目录
一.引言
二.Word2vec 简介
1.模型参数
2.Word2vec 网络
3.Skip-gram 与 CBOW
4.优化方法
4.1 负采样
4.2 层次 softmax
三.Word2vec 实战
1.数据预处理
2.模型训练与预测
3.模型与向量存取
4.模型 ReTrain 重训
5.向量可视化
四.总结 一.引言
词嵌入是一种…

自然语言处理从小白到大白系列(2)word Embedding从one-hot到word2vec
我们知道,对于我们的计算机来说,没有办法像人一样理解自然语言,在人工智能领域,这还有很长一段路要走,就算要直接处理自然语言,都很困难。因此,人们想办法把自然语言用数字的方式表示࿰…
Python实现Word2Vec(yandexdataschool/nlp_course)
学习github上的nlp课程https://github.com/yandexdataschool/nlp_course,以下是其中第一课embedding的实验部分seminar.iqynb的实现代码。https://github.com/yandexdataschool/nlp_course/blob/master/week01_embeddings/seminar.ipynb
看完上面那个实验教程基本就…
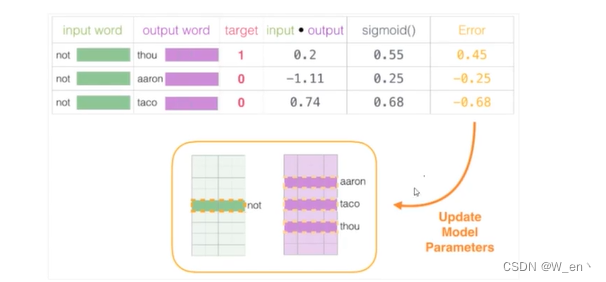
自然语言处理-词向量模型-Word2Vec
通常数据的维度越高,能提供的信息也就越多,从而计算结果的可靠性就更值得信赖 如何来描述语言的特征呢,通常都在词的层面上构建特征,Word2Vec就是要把词转换成向量 假设现在已经拿到一份训练好的词向量,其中每一个词都…
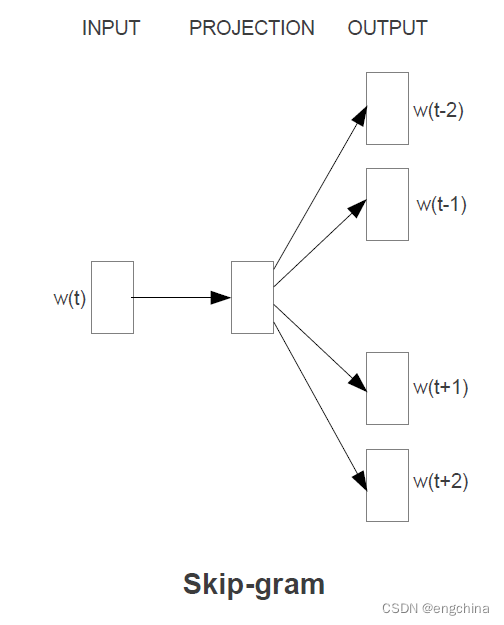
Word2vec 学习笔记
word2vec 学习笔记 0. 引言1. Word2vec 简介1-1. CBOW1-2. SG 2. 实战 0. 引言
最近研究向量检索,看到有同事使用 MeCab、Doc2Vec,所以把 Word2vec 这块知识学习一下。
1. Word2vec 简介
Word2vec 即 word to vector,顾名思义,…
gensim中word2vec使用
~~~~~~看了很多文章,对word2vec的原理讲解很清楚,还有一些源码解读和实现。但是在真正工作中如何熟练使用更是必须的。翻了下网页发现这个内容比较少。就记录一下关键它的使用。 ~~~~~~word2vec的实现是位于gensim包中gensim\models\word2vec.py文件里面…
python+Word2Vec实现中文聊天机器人
作为语言模型和文本挖掘中的常用工具,Word2Vec也可以用来构建聊天机器人。在本文中,我们将使用Python和Gensim库从头开始构建一个基于Word2Vec的中文聊天机器人。 1. 准备工作
在开始实现之前,我们需要准备一些数据和工具:
- [中…
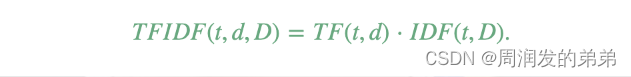
【SparkML系列3】特征提取器TF-IDF、Word2Vec和CountVectorizer
本节介绍了用于处理特征的算法,大致可以分为以下几组:
提取(Extraction):从“原始”数据中提取特征。转换(Transformation):缩放、转换或修改特征。选择(Selection&…
关于word2vec的一些相关问题整理 思考
1.简述word2vec基本思想,并简要描述CBOW和Skip-gram模型
word2vec的基本思想是一个词的意思, 可以由这个词的上下文来表示。 相似词拥有相似的上下文, 这也就是所谓的离散分布假设(distributional hypothesis)&#x…
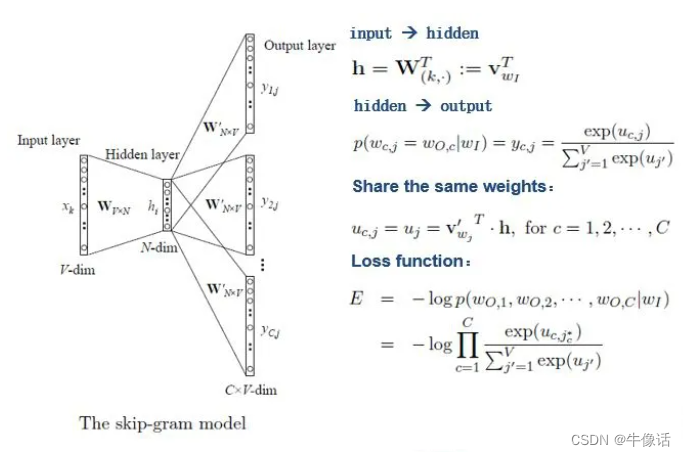
Embedding And Word2vec
Embedding与向量数据库:
Embedding 简单地说就是 N 维数字向量,可以代表任何东西,包括文本、音乐、视频等等。要创建一个Embedding有很多方法,可以使用Word2vec,也可以使用OpenAI 的 Ada。创建好的Embeddingÿ…

数据挖掘实战-基于word2vec的短文本情感分析(文末送书)
🤵♂️ 个人主页:艾派森的个人主页 ✍🏻作者简介:Python学习者 🐋 希望大家多多支持,我们一起进步!😄 如果文章对你有帮助的话, 欢迎评论 💬点赞Ǵ…
独热编码和Word2Vec的区别
独热编码和Word2Vec都是自然语言处理中将词向量化的方式,但它们之间并没有直接的关系或依赖性。它们可以被视为在处理词向量时的两种不同方法或策略。 独热编码是一种简单直观的方法,每个词被表示为一个长向量,其中只有一个元素是1࿰…
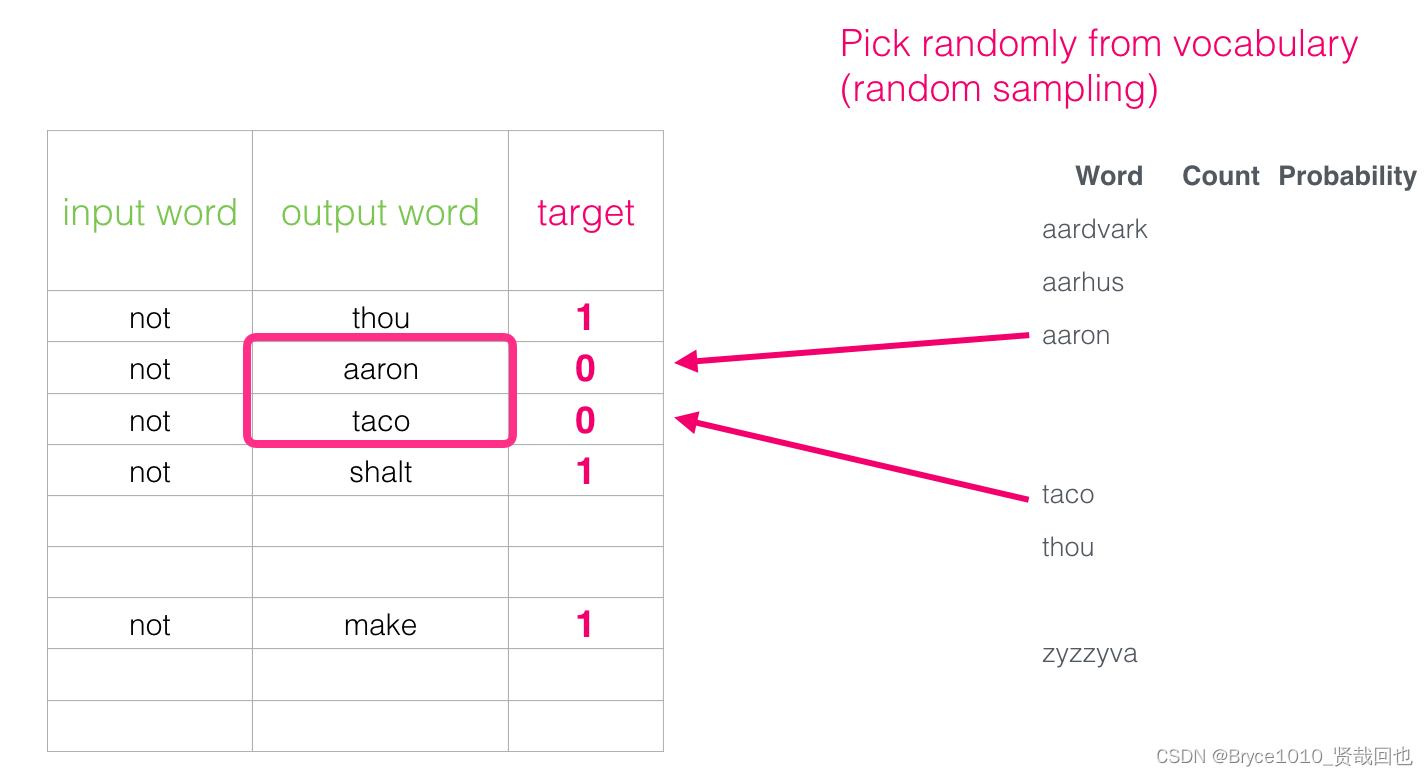
Word2Vec Efficient Estimation of Word Representations inVector Space论文笔记
Title
Mikolov T, Chen K, Corrado G, et al. Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781, 2013.
Summary
Word2vec是一种基于神经网络的自然语言处理技术,用于将单词表示为向量。这种技术的最大好处是它能…
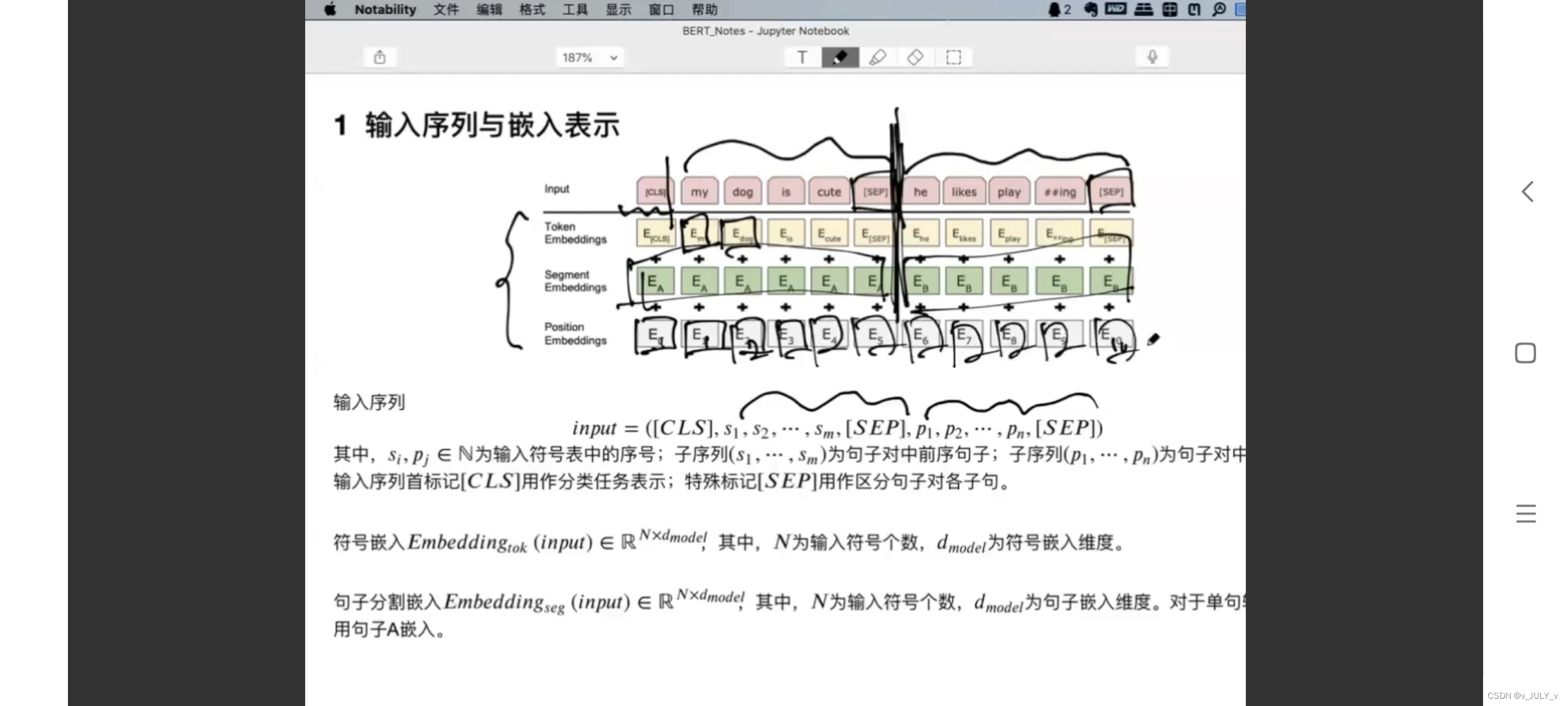
Transformer通俗笔记:从Word2Vec、Seq2Seq逐步理解到GPT、BERT
前言 我在写上一篇博客《22下半年》时,有读者在文章下面评论道:“july大神,请问BERT的通俗理解还做吗?”,我当时给他发了张俊林老师的BERT文章,所以没太在意。
直到今天早上,刷到CSDN上一篇讲B…
以ChatGPT为例进行自然语言处理学习——入门自然语言处理
⭐️我叫忆_恒心,一名喜欢书写博客的在读研究生👨🎓。 如果觉得本文能帮到您,麻烦点个赞👍呗! 近期会不断在专栏里进行更新讲解博客~~~ 有什么问题的小伙伴 欢迎留言提问欧,喜欢的小伙伴给个三…

自然语言处理(六):词的相似性和类比任务
词的相似性和类比任务
在前面的章节中,我们在一个小的数据集上训练了一个word2vec模型,并使用它为一个输入词寻找语义相似的词。实际上,在大型语料库上预先训练的词向量可以应用于下游的自然语言处理任务,为了直观地演示大型语料…

Word2Vec实战
Word2Vec实战 – 潘登同学的NLP学习笔记 文章目录Word2Vec实战 -- 潘登同学的NLP学习笔记回顾词向量算法Skip-gramWord2Vec代码实现拉取数据解压数据数据处理构造训练样本查看构造结果构造计算图画图函数Trian!结果回顾词向量算法
Skip-gram Word2Vec代码实现
这里采用Skip-g…

NLP成长计划(二)
Setup
假设您已经完成了(一)所需的设置。
在本讲座中,我们将使用 Gensim和NLTK,这两个广泛使用的Python自然语言处理库。 如果我们想要能够对文本进行分类,我们需要能够根据文章、段落、句子和文本的其他主体所包含的…
R语言中利用word2vec包创建词向量
介绍
将词汇向量化是自然语言处理的基本一步,这里解释如何利用R语言中的word2vec实现该功能。
函数word2vec()介绍
word2vec(x,type c("cbow", "skip-gram"),dim 50,window ifelse(type "cbow", 5L, 10L),iter 5L,lr 0.05,h…

word另存为pdf失败的原因及处理方法
我们知道,Word可以通过另存为方式直接保存为PDF,其原理其实跟打印机打印差不多,PDF就是一台虚拟的打印机,但有些同学反映word另存为pdf失败,可能的原因是什么呢?又该如何处理呢?
word另存为pdf…
词向量转换成句向量的文本相似度计算
# coding: utf-8# In[2]:
###读取已训练好的词向量
from gensim.models import word2vec
w2vword2vec.Word2Vec.load(d:/chat_data/corpus_vector.model)##对文本进行分词
import jieba
import re
raw_data []
w open(******,r,encoding utf-8)
for line in w.readlines():ne…
算法学习(十四)——word2vec
个人理解:就是获取一个没有偏置和激活函数的全连接隐层,将高维的one-hot数据转变为稠密、低维、有相似性的关系的矩阵,分为CBOW, skip-gram两种方法。
参考:
https://www.zhihu.com/question/45027109
https://www.jianshu.com…

Word Embedding与Word2Vec学习
一、词嵌入背景 Embed这个词,英文的释义为, fix (an object) firmly and deeply in a surrounding mass, 也就是“嵌入”之意。例如:One of the bullets passed through Andreas chest before embedding itself in a wall. 另外,这个词&#…

Word2Vec模型详解
文本向量化表示
对文本进行完预处理后,接下来的重要任务就是将文本用向量化的形式进行表达。在本章节中,我们将尽量全面地覆盖文本向量化表示方法,重点关注Word2Vec以及目前各种常用的词向量。
基于统计方法
首先,我们来看基于…